Transcribe your Podcast with accurate speaker diarisation, for free, with Whisper
Thanks to AI, automatic transcription has become affordable and accurate. But getting a reliable speaker diarisation is not easy… until you use Mufidiwiwhi!
The Podcasting 2.0 namespace allows podcasters to provide accurate transcription to their audience.
If you're a podcaster, make sure to choose a podcast hosting platform that supports transcripts (such as Castopod!). If you're a listener, pick an app that supports transcripts.
This will allow your podcast to embed transcripts and to make them available to your audience.
In order to create transcripts, you may use Whisper or Whisper.cpp.
Whisper is fast, free and accurate but it does not provide speaker diarisation.
Automatic diarisation is not an easy task. There are many solutions available but they are not as accurate as we would have hoped.
One incorrect word in an automatically generated transcript is something we usually accept, but displaying the wrong speaker name may make things too fuzzy. These solutions even sometimes fail to distinguish between female and male voices…
But if we take a step back, when we record a podcast, each speaker is recorded in a separate file, so what's the point of merging all speakers together, then struggle to separate them?!
We may as well run the transcription before merging all channels.
In order to do that, you can use Mumble to record a podcast with guests or use Ardour DAW to record a Podcast with several remote guests (you can also use Zrythm).
Once you have one file per speaker, all you have to do is transcribe and merge them into a single transcript file.
I developed a tiny, quick-and-dirty program using Whisper that does that: Mufidiwiwhi (Multi-file diarisation with Whisper). It will create 100% accurate diarisation.
All you have to do is provide the file names and speaker names:
mufidiwiwhi Lucy interview_lucy.mp3 Samir interview_samir.mp3 Rachel interview_rachel.mp3 --model large --language French
Then run it:
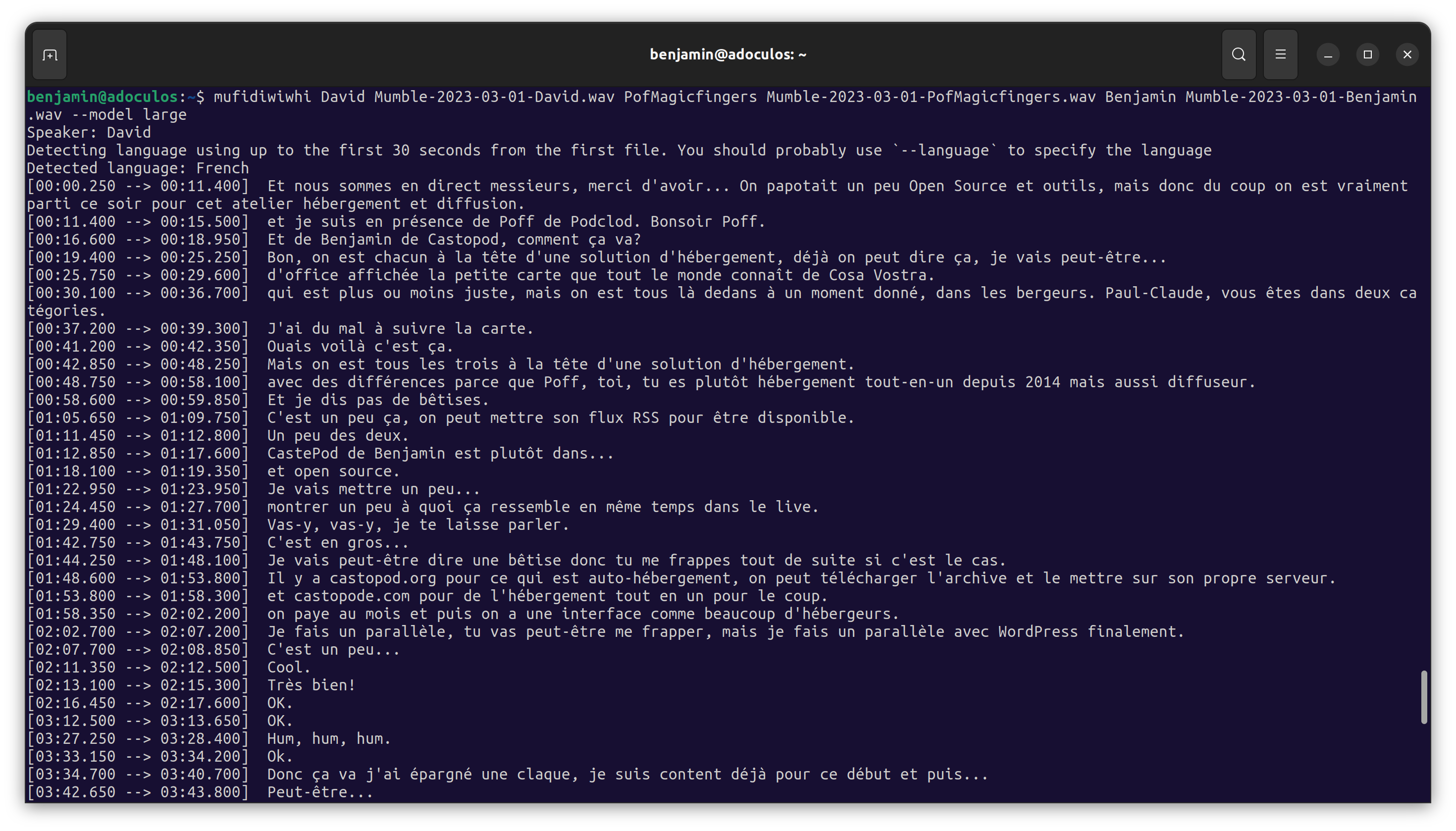
That's it!
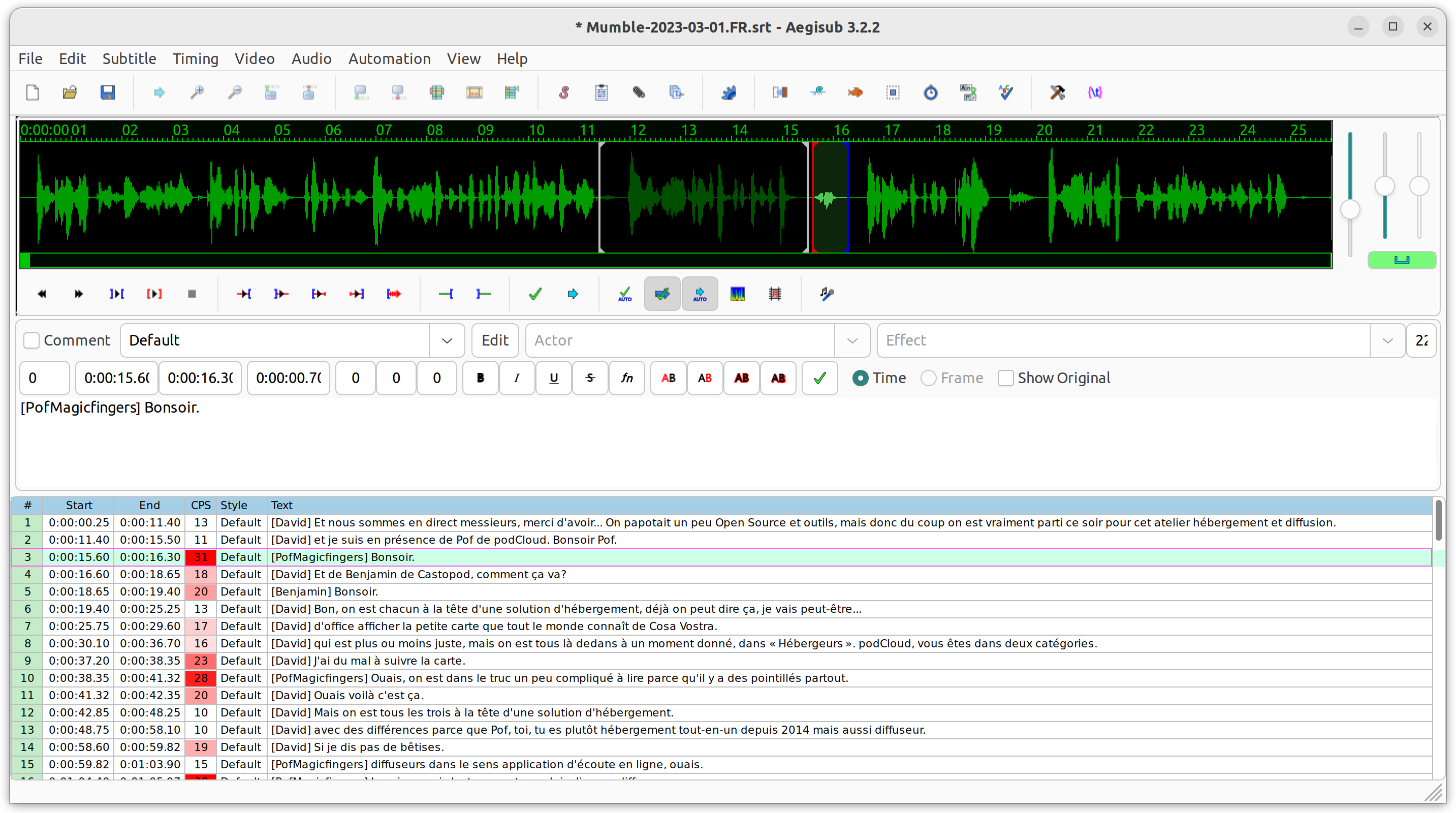
You may correct the result with any SRT editor:
Keep in mind that Mufidiwiwhi is built on top of Whisper so it accepts the same parameters.
You may use it for translation, generating SRT, json, etc.
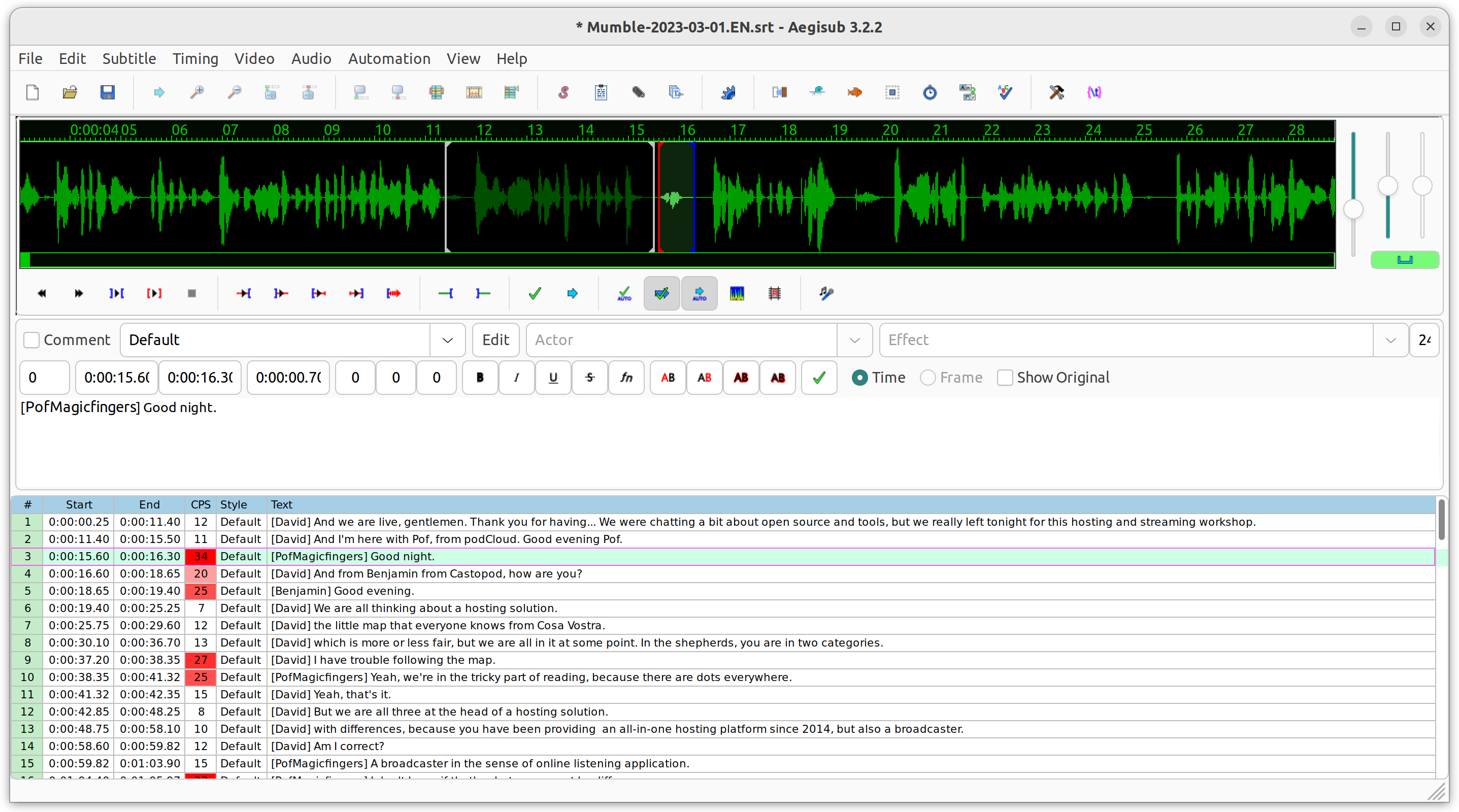
If you are lost, just type mufidiwiwhi --help
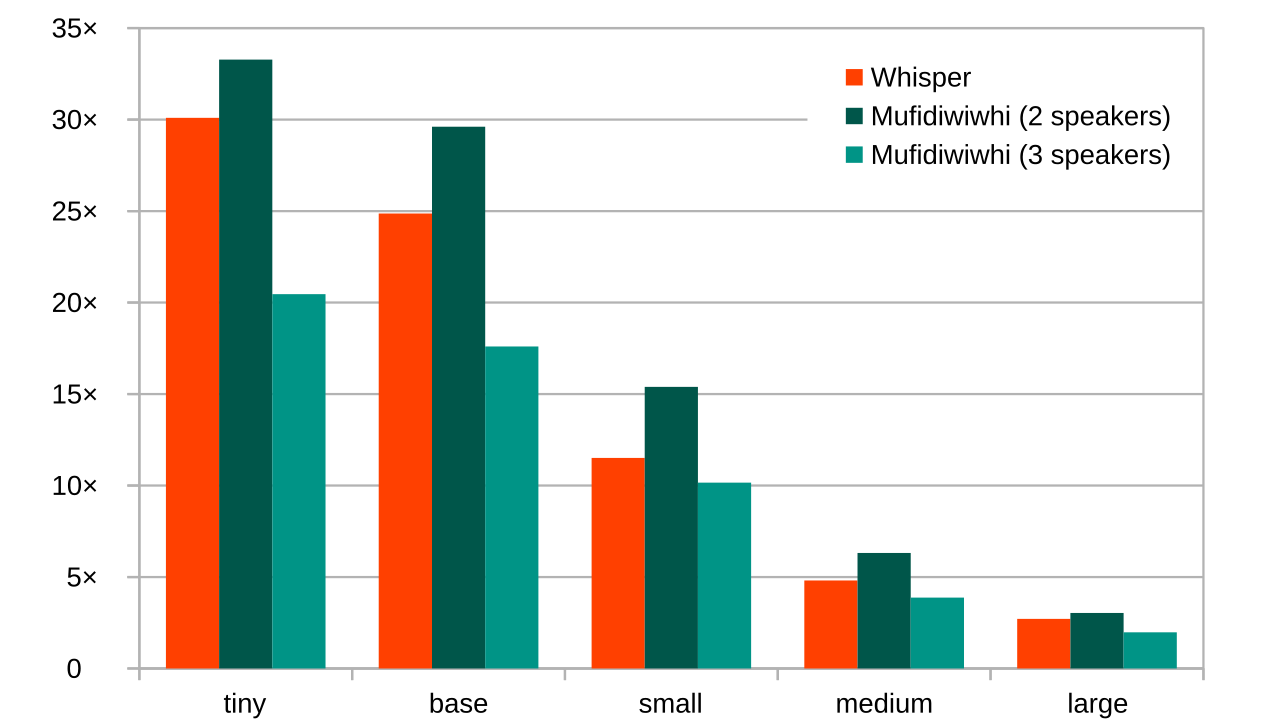
Benchmark
Mufidiwiwhi detects the silences and sends the rest to Whisper.
So if your files are correctly recorded (with good separation between all tracks) the time required should be almost the same.
We ran somes tests (on a 12GB Dual GeForce RTX 3060) on all models to compare how fast it runs.
With two speakers (2 audio tracks), Mufidiwiwhi is faster than Whisper, for both transcription and diarisation!
With three speakers (3 audio tracks), Mufidiwiwhi is slighly slower that Whisper.