Transcribe your podcast for free using only a laptop and Whisper
Whisper is a general-purpose speech recognition model that can be used for podcast transcription. It is open-source so you can download it with its multilingual trained model and use it on your personal laptop!
Transcription or Captioning?
First, let's get things straight: People often confuse transcription with captioning (and I must admit that I do too, shame on me…).
Even though they are alike and are usually generated by the same tools, they serve different purposes:
- A transcript is a plain text version of an audio file. It can be used if you want to read content without listening to it at the same time.
- A caption also embeds the timecodes for the text that was transcribed. It is usually displayed as subtitles.
That being said, we will use the “Transcription” term regardless of the purpose.
Who needs transcription?
There are many benefits to transcribing your podcast.
It will improve your audience's experience a lot:
- Accessibility: it will make your podcast accessible to the deaf and the hard of hearing.
- Translation: transcripts are easy to translate to other languages.
- Reaching new audiences: your audience may speak a language different from the one spoken in the podcast. That's why a transcript, translated or in the original language, will make the podcast easier to follow.
- Search engine indexing, searchability and SEO: with a searchable transcripted file your podcast is not “a collection of mp3 files with just a few metadata” anymore.
Eventually, your audience will be able to search for some keywords within an episode, within a whole show or even among thousands of podcasts!
Search engines will be able to understand what your podcast is really about and bring you more traffic and more listeners. - And so much more: see the last paragraph to learn more about what we do with transcription at Ad Aures…
Are transcripts for podcasts a real thing?
Yes they are!
Thanks to the Podcasting 2.0 initiative which proposed the Transcript tag, there are now over 25 (and counting…) services, apps and platforms that support transcripts (among them is Castopod which has been supporting the Transcript tag for nearly 2 years).
As a podcaster, if your hosting plaform does not allow the transcript tag, it's time you moved to a Podcasting 2.0 platform that does.
As a listener, if your podcast app does not show transcripts, it's time you opted for a new podcast app that does.
So how do I generate transcripts?
There are many API's and services that will help you for a small fee… as long as you don't have too many podcasts.
There are also many free and open-source tools, such as VOSK, but they are often cumbersome to install, they need some fine tuning and the results usually don't match your expectations.
Enter Whisper!
Whisper is easy to install and to use and its results are remarkable.
What is Whisper?
“Whisper is an automatic speech recognition (ASR) system trained on 680,000 hours of multilingual and multitask supervised data collected from the web. We show that the use of such a large and diverse dataset leads to improved robustness detection of accents, background noise and technical terms. Moreover, it enables transcription in multiple languages, as well as translation from those languages to English. We are open-sourcing models and inference code to serve as a foundation for building useful applications and for further research on robust speech processing.”
Whisper is open-source so you can download its source code from GitHub.
If you want to test it before installing it, you may run a 30 second test on Hugging Face:
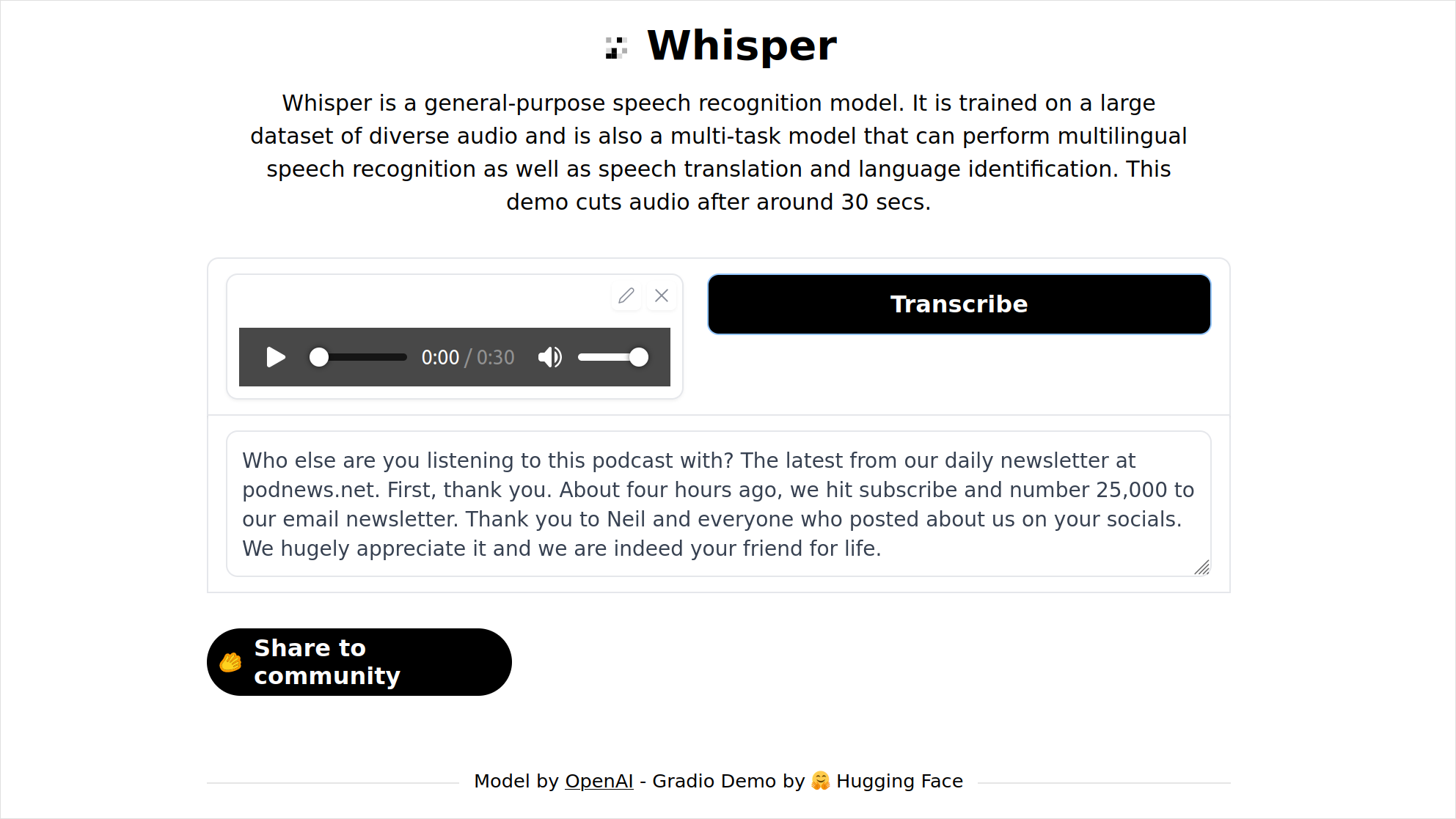
Quite impressive, isn't it?!
Whisper will automatically detect the language.
But if you want to, it can also translate the transcript to English!
Whisper can recognize many languages!
As you can see on the graph below, the WER (Word error rate) is really low (low is good): Whisper is very efficient.

Since the demo is limited to 30 seconds, how can you make it run on your laptop? Sounds tricky?
Actually it is not that difficult.
Let's install Whisper!
You need to know that Whisper needs many resources. So if your laptop is old and slow, Whisper may need hours to transcribe a 5mn podcast…
Therefore, although it is not mandatory, you probably need a GPU (ie. an expensive graphic card, nVidia or AMD ROCm) in order to make it transcribe faster.
Here is the bill of materials:
- a laptop (obviously…),
- a graphic card (optional but recommended)
- drivers for your graphic card,
- Python 3.6 or above,
- a package manager for Python (Anaconda is recommended but I used pip),
- PyTorch,
- Whisper,
- Some mp3 files you want to transcribe!
I am using a laptop running Ubuntu 22.04 but it should work on any Operating System.
So first check that your graphic adapter is working with the proper drivers.
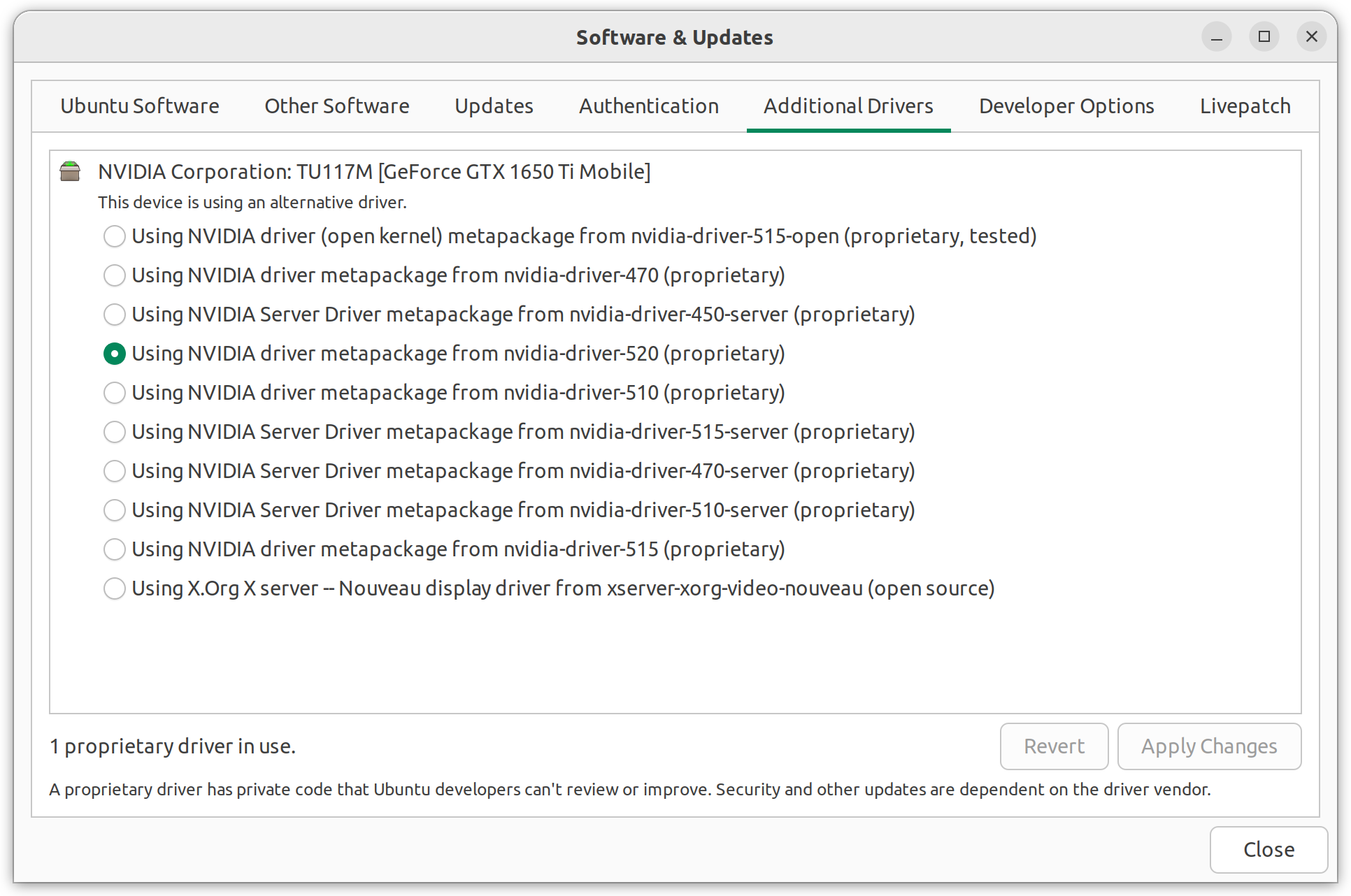
If your card is Nvidia you need to download and install CUDA Toolkit 11.8.
Just follow the instructions on Nvidia's website.
On my laptop, I had to type the following in a terminal:
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.0-1_all.deb
sudo dpkg -i cuda-keyring_1.0-1_all.deb
sudo apt-get update
sudo apt-get -y install cuda
You may also have to install CUDA Toolkit:
sudo apt-get -y install nvidia-cuda-toolkit
Now is probably a good time to reboot your laptop.
Check that everything is properly installed:
nvidia-smi
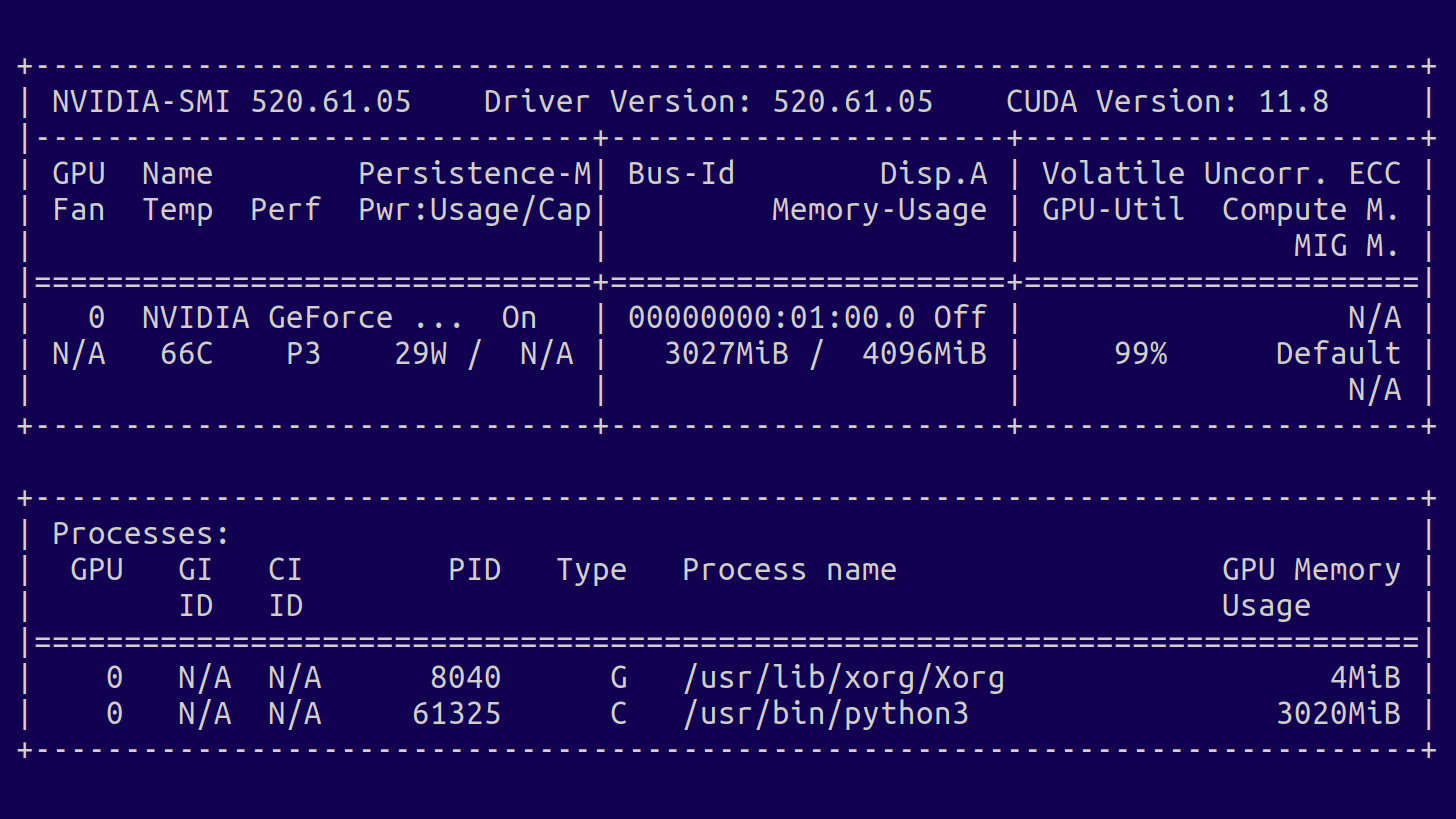
Here you need to check the CUDA version and the amount of memory installed on your GPU (here 4096MiB), you will need that value later to select a model.
Now you need to install PyTorch.
Follow the instructions on PyTorch's website.
On my laptop, I had to type the following in a terminal:
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu116
You are almost there!
You just need to install Whisper:
pip install git+https://github.com/openai/whisper.git
That's it!
Now you can run Whisper and transcribe all your podcasts (you may adapt the command according to your needs):
whisper test.mp3 --language French --model small --device cuda --fp16 False --verbose False
For instance, here is what it looks like:
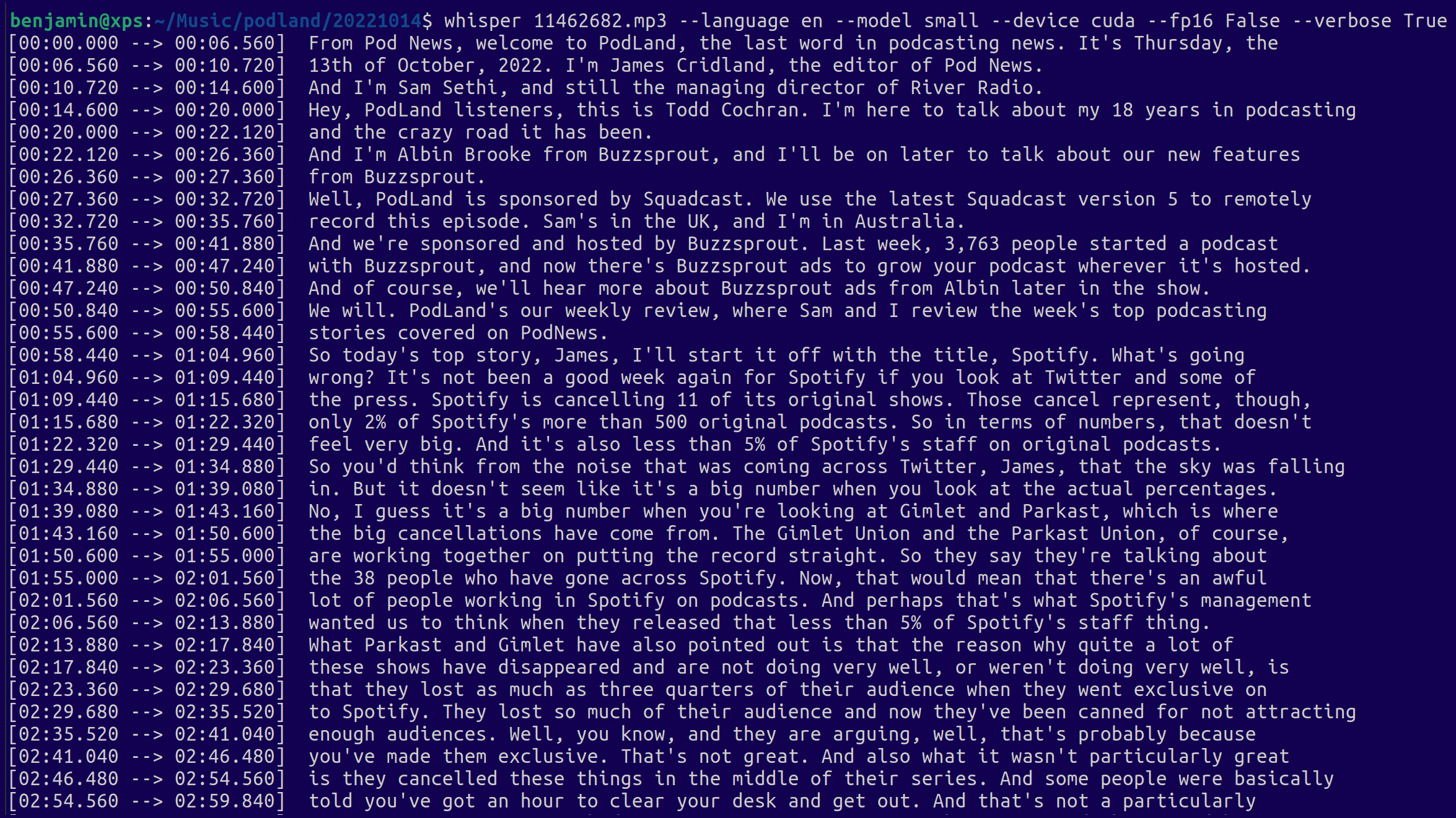
Whisper will generate 3 files:
- a plain text TXT transcript file,
- an SRT (which is the one we recommend you use for podcasting) caption file,
- a VTT caption file.
If you want to transcribe a whole folder (with sub-folders), you may run:
find . -name "*.mp3" -exec whisper {} --language French --model small --device cuda --fp16 False --verbose False \;
Happy transcribing! 📝
Note 1: whisper --help will give you all the parameters that are available.
Note 2: You may pick the largest model that your GPU can handle:
| Size | Multilingual model | Required VRAM |
|---|---|---|
| tiny | tiny |
~1 GB |
| base | base |
~1 GB |
| small | small |
~2 GB |
| medium | medium |
~5 GB |
| large | large |
~10 GB |
Note 3: if you are stuck or lost, a good place to find answers is Whisper's forum.
More about transcription, Castopod and Ad Aures…
At Ad Aures we have been working on speech recognition applied to podcasting for a while, using mainly VOSK (but we are now replacing VOSK with Whisper), some pre-processing (noise detection, cutting, …) and some post-processing (de-duplication, …). That allows us to provide semantic indexing, automatic chaptering, contextual recommendation and monetization.
We are also building some open-source correction tools for Castopod.







